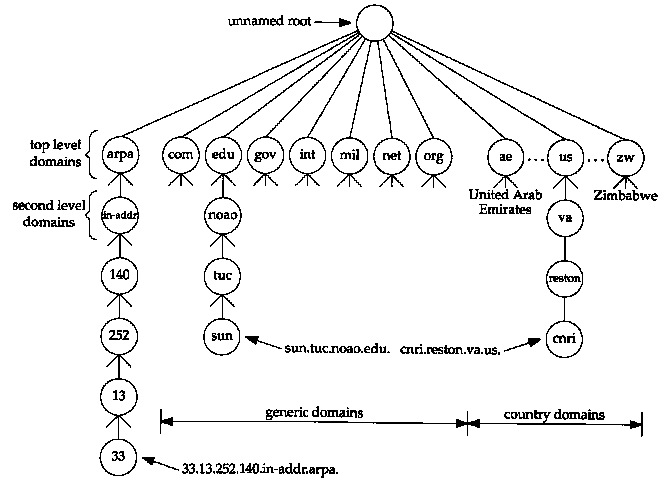
Figure 14.1 Hierarchical organization of the DNS.
The Domain Name System, or DNS, is a distributed database that is used by TCP/IP applications to map between hostnames and IP addresses, and to provide electronic mail routing information. We use the term distributed because no single site on the Internet knows all the information. Each site (university department, campus, company, or department within a company, for example) maintains its own database of information and runs a server program that other systems across the Internet (clients) can query. The DNS provides the protocol that allows clients and servers to communicate with each other.
From an application's point of view, access to the DNS is through a resolver. On Unix hosts the resolver is accessed primarily through two library functions, gethostbyname(3) and gethostbyaddr(3), which are linked with the application when the application is built. The first takes a hostname and returns an IP address, and the second takes an IP address and looks up a hostname. The resolver contacts one or more name servers to do the mapping.
In Figure 4.2 we showed that the resolver is normally part of the application. It is not part of the operating system kernel as are the TCP/IP protocols. Another fundamental point from this figure is that an application must convert a hostname to an IP address before it can ask TCP to open a connection or send a datagram using UDP. The TCP/IP protocols within the kernel know nothing about the DNS.
In this chapter we'll take a look at how resolvers communicate with name servers using the TCP/IP protocols (mainly UDP). We do not cover all the administrative details of running a name server or all the options available with resolvers and servers. These details can fill an entire book. (See [Albitz and Liu 1992] for all the details on the care and feeding of the standard Unix resolver and name server.)
RFC 1034 [Mockapetris 1987a] specifies the concepts
and facilities provided by the DNS, and RFC 1035 [Mockapetris
1987b] details the implementation and specification. The most
commonly used implementation of the DNS, both resolver and name
server, is called BIND-the Berkeley Internet Name Domain server.
The server is called named. An analysis of the wide-area network
traffic generated by the DNS is given in [Danzig, Obraczka, and
Kumar 1992].
14.2 DNS Basics
The DNS name space is hierarchical, similar to the Unix filesystem. Figure 14.1 shows this hierarchical organization.
Every node (circles in Figure 14.1) has a label of up to 63 characters. The root of the tree is a special node with a null label. Any comparison of labels considers uppercase and lowercase characters the same. The domain name of any node in the tree is the list of labels, starting at that node, working up to the root, using a period ("dot") to separate the labels. (Note that this is different from the Unix filesystem, which forms a pathname by starting at the top and going down the tree.) Every node in the tree must have a unique domain name, but the same label can be used at different points in the tree.
A domain name that ends with a period is called an absolute domain name or a fully qualified domain name (FQDN). An example is sun.tuc.noao.edu.. If the domain name does not end with a period, it is assumed that the name needs to be completed. How the name is completed depends on the DNS software being used. If the uncompleted name consists of two or more labels, it might be considered to be complete; otherwise a local addition might be added to the right of the name. For example, the name sun might be completed by adding the local suffix .tuc.noao.edu.. The top-level domains are divided into three areas:
Figure 14.2 lists the normal classification of the seven generic domains.
|
| commercial organizations |
|
| educational institutions |
|
| other U.S. governmental organizations |
|
| international organizations |
|
| U.S. military |
|
| networks |
|
| other organizations |
DNS folklore says that the 3-character generic domains are only for U.S. organizations, and the 2-character country domains for everyone else, but this is false. There are many non-U.S. organizations in the generic domains, and many U.S. organizations in the .us country domain. (RFC 1480 [Cooper and Postel 1993] describes the .us domain in more detail.) The only generic domains that are restricted to the United States are .gov and .mil.
Many countries form second-level domains beneath their 2-character country code similar to the generic domains: .ac.uk, for example, is for academic institutions in the United Kingdom and .co.uk is for commercial organizations in the United Kingdom.
One important feature of the DNS that isn't shown in figures such as Figure 14.1 is the delegation of responsibility within the DNS. No single entity manages every label in the tree. Instead, one entity (the NIC) maintains a portion of the tree (the top-level domains) and delegates responsibility to others for specific zones.
A zone is a subtree of the DNS tree that is administered separately. A common zone is a second-level domain, noao.edu, for example. Many second-level domains then divide their zone into smaller zones. For example, a university might divide itself into zones based on departments, and a company might divide itself into zones based on branch offices or internal divisions.
If you are familiar with the Unix filesystem, notice that the division of the DNS tree into zones is similar to the division of a logical Unix filesystem into physical disk partitions. Just as we can't tell from Figure 14.1 where the zones of authority lie, we can't tell from a similar picture of a Unix filesystem which directories are on which disk partitions.
Once the authority for a zone is delegated, it is up to the person responsible for the zone to provide multiple name servers for that zone. Whenever a new system is installed in a zone, the DNS administrator for the zone allocates a name and an IP address for the new system and enters these into the name server's database. This is where the need for delegation becomes obvious. At a small university, for example, one person could do this each time a new system was added, but in a large university the responsibility would have to be delegated (probably by departments), since one person couldn't keep up with the work.
A name server is said to have authority for one zone or multiple zones. The person responsible for a zone must provide a primary name server for that zone and one or more secondary name servers. The primary and secondaries must be independent and redundant servers so that availability of name service for the zone isn't affected by a single point of failure.
The main difference between a primary and secondary is that the primary loads all the information for the zone from disk files, while the secondaries obtain all the information from the primary. When a secondary obtains the information from its primary we call this a zone transfer.
When a new host is added to a zone, the administrator adds the appropriate information (name and IP address minimally) to a disk file on the system running the primary. The primary name server is then notified to reread its configuration files. The secondaries query the primary on a regular basis (normally every 3 hours) and if the primary contains newer data, the secondary obtains the new data using a zone transfer.
What does a name server do when it doesn't contain the information requested? It must contact another name server. (This is the distributed nature of the DNS.) Not every name server, however, knows how to contact every other name server. Instead every name server must know how to contact the root name servers. As of April 1993 there were eight root servers and all the primary servers must know the IP address of each root server. (These IP addresses are contained in the primary's configuration files. The primary servers must know the IP addresses of the root servers, not their DNS names.) The root servers then know the name and location (i.e., the IP address) of each authoritative name server for all the second-level domains. This implies an iterative process: the requesting name server must contact a root server. The root server tells the requesting server to contact another server, and so on. We'll look into this procedure with some examples later in this chapter.
You can fetch the current list of root servers using anonymous FTP. Obtain the file netinfo/root-servers.txt from either ftp.rs.internic.net or nic.ddn.mil.
A fundamental property of the DNS is caching.
That is, when a name server receives information about a mapping
(say, the IP address of a hostname) it caches that information
so that a later query for the same mapping can use the cached
result and not result in additional queries to other servers.
Section 14.7 shows an example of caching.
14.3 DNS Message Format
There is one DNS message defined for both queries
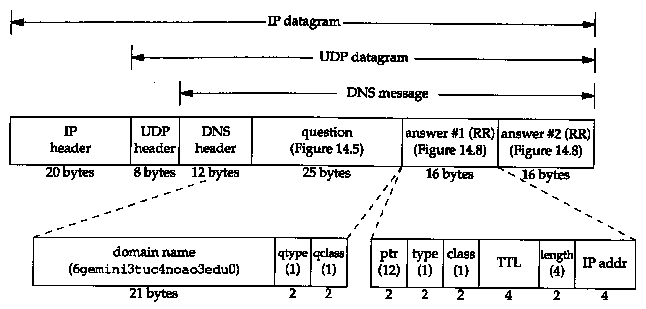
and responses. Figure 14.3 shows the overall format of the message.
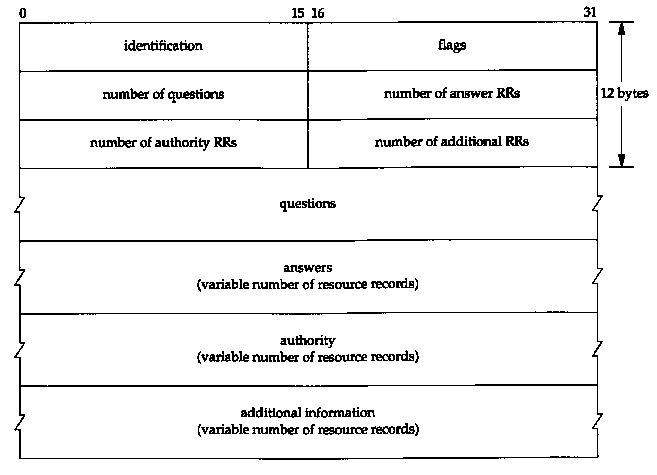
The message has a fixed 12-byte header followed by four variable-length fields.
The identification is set by the client and returned by the server. It lets the client match responses to requests.
The 16-bit flags field is divided into numerous pieces, as shown in Figure 14.4.

We'll start at the leftmost bit and describe each field.
The next four 16-bit fields specify the number of entries in the four variable-length fields that complete the record. For a query, the number of questions is normally 1 and the other three counts are 0. Similarly, for a reply the number of answers is at least 1, and the remaining two counts can be 0 or nonzero.
The format of each question in the question section is shown in Figure 14.5. There is normally just one question.
The query name is the name being looked up. It is a sequence of one or more labels. Each label begins with a 1-byte count that specifies the number of bytes that follow. The name is terminated with a byte of 0, which is a label with a length of 0, which is the label of the root. Each count byte must be in the range of 0 to 63, since labels are limited.
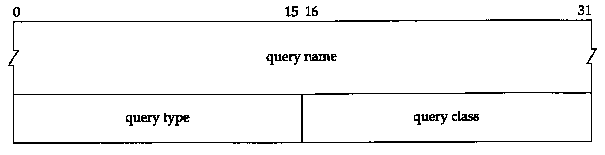
to 63 bytes. (We'll see later in this section that a count byte with the two high-order bits turned on, values 192 to 255, is used with a compression scheme.) Unlike many other message formats that we've encountered, this field is allowed to end on a boundary other than a 32-bit boundary. No padding is used. Figure 14.6 shows how the domain name gemini.tuc.noao.edu is stored.

Each question has a query type and each response (called a resource record, which we talk about below) has a type. There are about 20 different values, some of which are now obsolete. Figure 14.7 shows some of these values. The query type is a superset of the type: two of the values we show can be used only in questions.
value | type? | |||
| A NS CNAME PTR HINFO MX | 2 5 12 13 15 | IP address name server canonical name pointer record host info mail exchange record | * * * * * | * * * * * |
| AXFR * or ANY | 255 | request for zone transfer request for all records | * |
The most common query type is an A type, which means an IP address is desired for the query name. A PTR query requests the names corresponding to an IP address. This is a pointer query that we describe in Section 14.5. We describe the other query types in Section 14.6.
The query class is normally 1, meaning Internet address. (Some other non-IP values are also supported at some locations.)
The final three fields in the DNS message, the answers, authority, and additional information fields, share a common format called a resource record or RR. Figure 14.8 shows the format of a resource record.
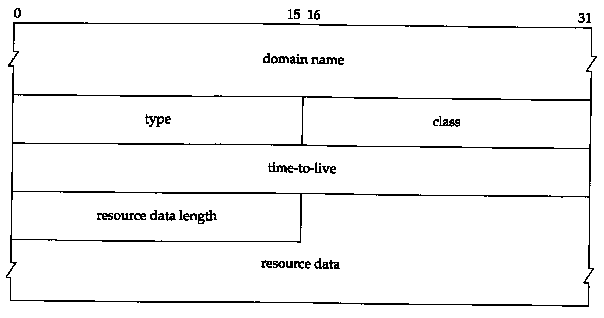
The domain name is the name to which the following resource data corresponds. It is in the same format as we described earlier for the query name field (Figure 14.6).
The type specifies one of the RR type codes. These are the same as the query type values that we described earlier. The class is normally 1 for Internet data.
The time-to-live field is the number of seconds that the RR can be cached by the client. RRs often have a TTL of 2 days.
The resource data length specifies the amount of resource data. The format of this data depends on the type. For a type of 1 (an A record) the resource data is a 4-byte IP address.
Now that we've described the basic format of the
DNS queries and responses, we'll see what is passed in the packets
by watching some exchanges using tcpdump.
14.4 A Simple Example
Let's start with a simple example to see the communication between a resolver and a name server. We'll run the Telnet client on the host sun to the host gemini, connecting to the daytime server:
| sun % telnet gemini daytime Trying 140.252.1.11 ... Connected to gemini. tuc.noao.edu. Escape character is '^]' Wed Mar 24 10:44:17 1993 Connection closed by foreign host. | first three lines of output are from Telnet client this is the output from the daytime server and this is from the Telnet client |
For this example we direct the resolver on the host sun (where the Telnet client is run) to use the name server on the host noao.edu (140.252.1.54). Figure 14.9 shows the arrangement of the three systems.
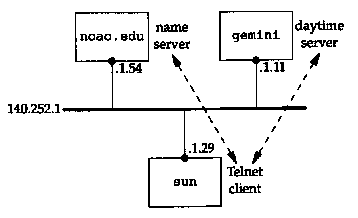
As we've mentioned before, the resolver is part of the client, and the resolver contacts a name server to obtain the IP address before the TCP connection can be established between Telnet and the daytime server.
In this figure we've omitted the detail that the connection between sun and the 140.252.1 Ethernet is really a SLIP link (see the figure on the inside front cover) because that doesn't affect the discussion. We will, however, run tcpdump on the SLIP link to see the packets exchanged between the resolver and name server.
The file /etc/resolv.conf on the host sun tells the resolver what to do:
sun % cat /etc/resolv.conf
nameserver 140.252.1.54
domain tuc.noao.edu
The first line gives the IP address of the name server - the host noao.edu. Up to three nameserver lines can be specified, to provide backup in case one is down or unreachable. The domain line specifies the default domain. If the name being looked up is not a fully qualified domain name (it doesn't end with a period) then the default domain .tuc.noao.edu is appended to the name. This is why we can type telnet gemini instead of telnet gemini.tuc.noao.edu. Figure 14.10 shows the packet exchange between the resolver and name server.
| 1 | 0.0 | 140.252.1.29.1447 > 140.252.1.54.53: 1+ A?
gemini.tuc.noao.edu. (37) |
| 2 | 0.290820 (0.2908) | 140.252.1.54.53 > 140.252.1.29.1447: 1* 2/0/0 A
140.252.1.11 (69) |
We've instructed tcpdump not to print domain names for the source and destination IP addresses of each IP datagram. Instead it prints 140.252.1.29 for the client (the resolver) and 140.252.1.54 for the name server. Port 1447 is the ephemeral port used by the client and 53 is the well-known port for the name server. If tcpdump had tried to print names instead of IP addresses, then it would have been contacting the same name server (doing pointer queries), confusing the output.
Starting with line 1, the field after the colon (1+) means the identification field is 1, and the plus sign means the RD flag (recursion desired) is set. We see that by default, the resolver asks for recursion.
The next field, A?, means the query type is A (we want an IP address), and the question mark indicates it's a query (not a response). The query name is printed next: gemini.tuc.noao.edu.. The resolver added the final period to the query name, indicating that it's an absolute domain name.
The length of user data in the UDP datagram is shown as 37 bytes: 12 bytes are the fixed-size header (Figure 14.3); 21 bytes for the query name (Figure 14.6), and 4 bytes for the query type and query class. The odd-length UDP datagram reiterates that there is no padding in the DNS messages.
Line 2 in the tcpdump output is the response from the name server and 1* is the identification field with the asterisk meaning the AA flag (authoritative answer) is set. (We expect this server, the primary server for the noao.edu domain, to be authoritative for names within its domain.)
The output 2/0/0 shows the number of resource records in the final three variable-length fields in the response: 2 answer RRs, 0 authority RRs, and 0 additional RRs. tcpdump only prints the first answer, which in this case has a type of A (IP address) with a value of 140.252.1.11.
Why do we get two answers to our query? Because the host gemini is multihomed. Two IP addresses are returned. Indeed, another useful tool with the DNS is a publicly available program named host. It lets us issue queries to a name server and see what comes back. If we run this program we'll see the two IP addresses for this host:
| sun % host gemini | ||
| gemini.tuc.noao.edu | A | 140.252.1.11 |
| gemini.tuc.noao.edu | A | 140.252.3.54 |
The first answer in Figure 14.10 and the first line of output from the host command are the IP address that shares the same subnet (140.252.1) as the requesting host. This is not an accident. If the name server and the host issuing the query are on the same network (or subnet), then BIND sorts the results so that addresses on common networks appear first.
We can still access the host gemini using the other address, but it might be less efficient. Using traceroute in this instance shows that the normal route from subnet 140.252.1 to 140.252.3 is not through the host gemini, but through another router that's connected to both networks. So in this case if we accessed gemini through the other IP address (140.252.3.54) all the packets would require an additional hop. We return to this example and explore the reason for the alternative route in Section 25.9, when we can use SNMP to look at a router's routing table.
There are other programs that provide easy interactive access to the DNS. nslookup is supplied with most implementations of the DNS. Chapter 10 of [Albitz and Liu 1992] provides a detailed description of how to use this program. The dig program ("Domain Internet Groper") is another publicly available tool that queries DNS servers, doc ("Domain Obscenity Control") is a shell script that uses dig and diagnoses misbehaving domains by sending queries to the appropriate DNS name servers, and performing simple analysis of the responses. See Appendix F for details on how to obtain these programs.
The final detail to account for in this example is the size of the UDP data in the reply: 69 bytes. We need to know two points to account for these bytes.
The compression scheme is simple. Anywhere the label portion of a domain name can occur, the single count byte (which is between 0 and 63) has its two high-order bits turned on instead. This means it is a 16-bit pointer and not an 8-bit count byte. The 14 bits that follow in the pointer specify an offset in the DNS message of a label to continue with. (The offset of the first byte in the identification field is 0.) We purposely said that this pointer can occur wherever a label can occur, not just where a complete domain name can. occur, since it's possible for a pointer to form either a complete domain name or just the ending portion of a name. (This is because the ending labels in the names from a given domain tend to be identical.)
Figure 14.11 shows the format of the DNS reply, line 2 from Figure 14.10. We also show the IP and UDP headers to reiterate that DNS messages are normally encapsulated in UDP datagrams. We explicitly show the count bytes in the labels of the domain name in the question. The two answers returned are the same, except for the different IP addresses returned in each answer. In this example the pointer in each answer would have a value of 12, the offset from the start of the DNS header of the complete domain name.
The final point to note from this example is from the second line of output from the Telnet command, which we repeat here:
| sun % telnet gemini daytime | we only type gemini |
| Trying 140.252.1.11 | |
| ... Connected to gemini.tuc.noao.edu. | but the Telnet client outputs FQDN |
We typed just the hostname (gemini), not the FQDN, but the Telnet client output the FQDN. What's happening is that the Telnet client looks up the name we type by calling
the resolver (gethostbyname), which returns the IP addresses and the FQDN. Telnet then prints the IP address that it's trying to establish a TCP connection with, and when the connection is established, it outputs the FQDN.
If there is a significant pause between typing the
Telnet command and printing the IP address, this delay is caused
by the resolver contacting a name server to resolve the name into
an IP address. A pause between printing Trying
and Connected to, however, is a delay
caused by the establishment of the TCP connection between the
client and server, not the DNS.
14.5 Pointer Queries
A perpetual stumbling block in understanding the DNS is how pointer queries are handled - given an IP address, return the name (or names) corresponding to that address.
First return to Figure 14.1 and examine the arpa top-level domain, and the in-addr domain beneath it. When an organization joins the Internet and obtains authority for a portion of the DNS name space, such as noao.edu, they also obtain authority for a portion of the in-addr.arpa name space corresponding to their IP address on the Internet. In the case of noao.edu it is the class B network ID 140.252. The level of the DNS tree beneath in-addr.arpa must be the first byte of the IP address (140 in this example), the next level is the next byte of the IP address (252), and so on. But remember that names are written starting at the bottom of the DNS tree, working upward. This means the DNS name for the host sun, with an IP address of 140.252.13.33, is 33.13.252.140. in-addr.arpa.
We have to write the 4 bytes of the IP address backward because authority is delegated based on network IDs: the first byte of a class A address, the first and second bytes of a class B address, and the first, second, and third bytes of a class C address. The first byte of the IP address must be immediately below the in-addr label, but FQDNs are written from the bottom of the tree up. If FQDNs were written from the top down, then the DNS name for the IP address would be arpa.in-addr.140.252.13.33, but the FQDN for the host would be edu.noao.tuc.sun.
If there was not a separate branch of the DNS tree for handling this address-to-name translation, there would be no way to do the reverse translation other than starting at the root of the tree and trying every top-level domain. This could literally take days or weeks, given the current size of the Internet. The in-addr.arpa solution is a clever one, although the reversed bytes of the IP address and the special domain are confusing.
Having to worry about the in-addr.arpa domain and reversing the bytes of the IP address affects us only if we're dealing directly with the DNS, using a program such as host, or watching the packets with tcpdump. From an application's point of view, the normal resolver function (gethostbyaddr) takes an IP address and returns information about the host. The reversal of the bytes and appending the domain in-addr.arpa are done automatically by this resolver function.
Let's use the host program to do a pointer lookup and watch the packets with tcpdump. We'll use the same setup as in Figure 14.9, running the host program on the host sun, and the name server on the host noao.edu. We specify the IP address of our host svr4:
sun % host 140.252.13.34
Name: svr4.tuc.noao.edu
Address: 140.252.13.34
Since the only command-line argument is an IP address, the host program automatically generates the pointer query. Figure 14.12 shows the tcpdump output.
| 1 | 0.0 | 140.252.1.29.1610 > 140.252.1.54.53: 1+ PTR?
34.13.252.140.in-addr.arpa. (44) |
| 2 | 0.332288 (0.3323) | 140.252.1.54.53 > 140.252.1.29.1610: 1* 1/0/0 PTR
svr4.tuc.noao.edu. (75) |
Line 1 shows that the identifier is 1, the recursion-desired flag is set (the plus sign), and the query type is PTR. (Recall that the question mark means this is a query and not a response.) The data size of 44 bytes is from the 12-byte DNS header, 28 bytes for the 7 labels in the domain name, and 4 bytes for the query type and query class.
The reply has the authoritative-answer bit set (the asterisk) and contains one answer RR. The RR type is PTR and the resource data contains the domain name.
What is passed from the resolver to the name server for a pointer query is not a 32-bit IP address, but the domain name 34.13.252.140.in-addr.arpa.
When an IP datagram arrives at a host for a server, be it a UDP datagram or a TCP connection request segment, all that's available to the server process is the client's IP address and port number (UDP or TCP). Some servers require the client's IP address to have a pointer record in the DNS. We'll see an example of this, using anonymous FTP from an unknown IP address, in Section 27.3.
Other servers, such as the Rlogin server (Chapter 26), not only require that the client's IP address have a pointer record, but then ask the DNS for the IP addresses corresponding to the name returned in the PTR response, and require that one of the returned addresses match the source IP address in the received datagram. This check is because entries in the .rhosts file (Section 26.2) contain the hostname, not an IP address, so the server wants to verify that the hostname really corresponds to the incoming IP address.
Some vendors automatically put this check into their resolver routines, specifically the function gethostbyaddr. This makes the check available to any program using the resolver, instead of manually placing the check in each application.
We can see an example of this using the SunOS 4.1.3 resolver library. We have written a simple program that performs a pointer query by calling the function gethostbyaddr. We have also set our /etc/resolv.conf file to use the name server on the host noao.edu, which is across the SLIP link from the host sun. Figure 14.13 shows the tcpdump output collected on the SLIP link when the function gethostbyaddr is called to fetch the name corresponding to the IP address 140.252.1.29 (our host sun).
| 1 | 0.0 | sun. 1812 > noao.edu.domain: 1+ PTR?
29.1.252.140.in-addr.arpa. (43) |
| 2 | 0.339091 (0.3391) | noao.edu.domain > sun.1812: 1* 1/0/0 PTR
sun.tuc.noao.edu. (73) |
| 3 | 0.344348 (0.0053) | sun. 1813 > noao.edu.domain: 2+ A?
sun.tuc.noao.edu. (33) |
| 4 | 0.669022 (0.3247) | noao.edu.domain > sun.1813: 2* 2/0/0 A
140.252.1.29 (69) |
Line 1 is the expected pointer query, and line 2
is the expected response. But the resolver function automatically
sends an IP address query in line 3 for the name returned in line
2. The response in line 4 contains two answer records, since the
host sun has two IP addresses. If one of the addresses does not
match the argument to gethostbyaddr,
a message is sent to the system logging facility, and the function
returns an error to the application.
14.6 Resource Records
We've seen a few different types of resource records (RRs) so far: an IP address has a type of A, and PTR means a pointer query. We've also seen that RRs are what a name server returns: answer RRs, authority RRs, and additional information RRs. There are about 20 different types of resource records, some of which we'll now describe. Also, more RR types are being added over time.
| A | An A record defines an IP address. It is stored as a 32-bit binary value. |
| PTR | This is the pointer record used for pointer queries. The IP address is represented as a domain name (a sequence of labels) in the in-addr.arpa domain. |
| CNAME | This stands for "canonical name." It is represented as a domain name (a sequence of labels). The domain name that has a canonical name is often called an alias. These are used by some FTP sites to
provide an easy to remember alias for some other system.
For example, the gated server (mentioned in Section 10.3) is available through anonymous FTP from the server gated.cornell.edu. But there is no system named gated, this is an alias for some other system. That other system is the canonical name for gated.cornell.edu:
sun % host -t cname gated.cornell.edu Here we use the -t option to specify one particular query type. |
| HINFO | Host information: two arbitrary character strings specifying the CPU and operating system. Not all sites provide HINFO records for all their systems, and the information provided may not be up to date.
sun % host -t hinfo sun |
| MX | Mail exchange records, which are used in the following scenarios: (1) A site that is not connected to the Internet can get an Internet-connected site to be its mail exchanger. The two sites then work out an alternati
ve way to exchange any mail that arrives, often using the UUCP protocol. (2) MX records provide a way to deliver mail to an alternative host when the destination host is not available. (3) MX records allow organizations to provide virtual hosts that one
can send mail to, such as cs.university.edu, even if a host with that name doesn't exist. (4) Organizations with firewall gateways can use MX records to limit connectivity to internal systems.
Many sites that are not connected to the Internet have a UUCP link with an Internet connected site such as UUNET. MX records are then provided so that electronic mail can be sent to the site using the standard user@host notation. For example, a fictitious domain foo.com might have the following MX records:
sun % host -t mx foo.com MX records are used by mailers on hosts connected to the Internet. In this example the other mailers are told "if you have mail to send to user@foo.com, send the mail to relay1.uu.net or relay2.uu.net." MX records have 16-bit integers assigned to them, called preference values. If multiple MX records exist for a destination, they're used in order, starting with the smallest preference value. Another example of MX records handles the case when a host is down or unavailable. In that case the mailer uses the MX records only if it can't connect to the destination using TCP. In the case of the author's primary system, which is connected to the In ternet by a SLIP connection, which is down most of the time, we have:
sun % host -tv mx sun We also specified the -v option, to see the preference values. (This option also causes other fields to be output.) The second field, 86400, is the time-to-live value in seconds. This TTL is 24 hours (24 x 60 x 60). The third column, IN, is the class (Internet). We see that direct delivery to the host itself, the first MX record, has the lowest preference value of 0. If that doesn't work (i.e., the SLIP link is down), the next higher preference is used (10) and delivery is attempted to the host noao.edu. If that doesn't work, the sender will time out and retry at a later time. In Section 28.3 we show examples of SMTP mail delivery using MX records. |
| NS | Name server record. These specify the authoritative name server for a domain. They are represented as domain names (a sequence of labels). We'll see examples of these records in the next section. |
These are the common types of RRs. We'll encounter
many of them in later examples.
14.7 Caching
To reduce the DNS traffic on the Internet, all name servers employ a cache. With the standard Unix implementation, the cache is maintained in the server, not the resolver. Since the resolver is part of each application, and applications come and go, putting the cache into the program that lives the entire time the system is up (the name server) makes sense. This makes the cache available to any applications that use the server. Any other hosts at the site that use this name server also share the server's cache.
In the scenario that we've used for our examples so far (Figure 14.9), we've run the clients on the host sun accessing the name server across the SLIP link on the host noao.edu. We'll change that now and run the name server on the host sun. In this way if we monitor the DNS traffic on the SLIP link using tcpdump, we'll only see queries that can't be handled by the server out of its cache.
By default, the resolver looks for a name server on the local host (UDP port 53 or TCP port 53). We delete the nameserver directive from our resolver file, leaving only the domain directive:
sun % cat /etc/resolv.conf
domain tuc.noao.edu
The absence of a nameserver directive in this file causes the resolver to use the name server on the local host.
We then use the host command to execute the following query:
sun % host ftp.uu.net
ftp.uu.net A 192.48.96.9
Figure 14.14 shows the tcpdump output for this query.
| 1 | 0.0 | sun.tuc.noao.edu.domain > NS.NIC.DDN.MIL.domain:
2 A? ftp.uu.net. (28) |
| 2 | 0.559285 ( 0.5593) | NS.NIC.DDN.MIL.domain > sun.tuc.noao.edu.domain:
2- 0/5/5 (229) |
| 3 | 0.564449 ( 0.0052) | sun.tuc.noao.edu.domain > ns.UU.NET.domain:
3+ A? ftp.uu.net. (28) |
| 4 | 1.009476 ( 0.4450) | ns.UU.NET.domain > sun.tuc.noao.edu.domain:
3* 1/0/0 A ftp.UU.NET (44) |
This time we've used a new option for tcpdump. We collected all the data to or from UDP or TCP ports 53 with the -w option. This saves the raw output in a file for later processing. This prevents tcpdump from trying to call the resolver itself, to print all the names corresponding to the IP addresses. After we ran our queries, we terminated tcpdump and reran it with the -r option. This causes it to read the raw output file and generate its normal printed output (which we show in Figure 14.14). This takes a few seconds, since tcpdump calls the resolver itself.
The first thing to notice in our tcpdump output is that the identifiers are small integers (2 and 3). This is because we terminated the name server, and then restarted it, to force the cache to be empty. When the name server starts up, it initializes the identifier to 1.
When we type our query, looking for the IP address of the host ftp.uu.net, the name server contacts one of the eight root servers, ns.nic.ddn.mil (line 1). This is the normal A type query that we've seen before, but notice that the recursion-desired flag is not specified. (A plus sign would have been printed after the identifier 2 if the flag was set.) In our earlier examples we always saw the resolver set the recursion-desired flag, but here we see that our name server doesn't set the flag when it's contacting one of the root servers. This is because the root servers shouldn't be asked to recursively answer queries-they should be used only to find the addresses of other, authoritative servers.
Line 2 shows that the response comes back with no answer RRs, five authority RRs, and five additional information RRs. The minus sign following the identifier 2 means the recursion-available (RA) flag was not set-this root server wouldn't answer a recursive query even if we asked it to.
Although tcpdump doesn't print the 10 RRs that are returned, we can execute the host command to see what's in the cache:
| sun % host -v ftp.uu.net | ||||
| Query about ftp.uu.net for record types A | ||||
| Trying ftp.uu.net ... | ||||
| Query done, 1 answer, status: no error | ||||
| The following answer is not authoritative: | ||||
| ftp.uu.net | 19109 | IN | A | 192.48.96.9 |
| Authoritative nameservers: | ||||
| UU.NET | 170308 | IN | NS | NS.UU.NET |
| UU.NET | 170308 | IN | NS | UUNET.UU.NET |
| UU.NET | 170308 | IN | NS | UUCP-GW-1.PA.DEC.COM |
| UU.NET | 170308 | IN | NS | UUCP-GW-2.PA.DEC.COM |
| UU.NET | 170308 | IN | NS | NS.EU.NET |
| Additional information: | ||||
| NS.UU.NET | 170347 | IN | A | 137.39.1.3 |
| UUNET.UU.NET | 170347 | IN | A | 192.48.96.2 |
| UUCP-GW-1.PA.DEC.COM | 170347 | IN | A | 16.1.0.18 |
| UUCP-GW-2.PA.DEC.COM | 170347 | IN | A | 16.1.0.19 |
| NS.EU.NET | 170347 | IN | A | 192.16.202.11 |
This time we specified the -v option to see more than just the A record. This shows that there are five authoritative name servers for the domain uu.net. The five RRs with additional information that are returned by the root server contain the IP addresses of these five name servers. This saves us from having to contact the root server again, to look up the address of one of the servers. This is another implementation optimization in the DNS.
The host command states that the answer is not authoritative. This is because the answer was obtained from our name server's cache, not by contacting an authoritative server.
Returning to line 3 of Figure 14.14, our name server contacts the first of the authoritative servers (ns.uu.net) with the same question: What is the IP address of ftp.uu.net? This time our server sets the recursion-desired flag. The answer is returned on line 4 as a response with one answer RR.
We then execute the host command again, asking for the same name:
sun % host ftp.uu.net
ftp.uu.net A 192.48.96.9
This time there is no tcpdump output. This is what we expect, since the answer output by host is returned from the server's cache.
We execute the host command again, looking for the address of ftp.ee.lbl.gov:
| sun%hostftp.ee.lbl.gov | ||
| ftp.ee.lbl.gov | CNAME | ee.lbl.gov |
| ee.lbl.gov | A | 128.3.112.20 |
Figure 14.15 shows the tcpdump output.
| 1 | 18.664971 (17.6555) | sun.tuc.noao.edu.domain > c.nyser.net.domain: 4 A? ftp.ee.lbl.gov. (32) |
| 2 | 19.429412 ( 0.7644) | c.nyser.net.domain > sun.tuc.noao.edu.domain:
4 0/4/4 (188) |
| 3 | 19.432271 ( 0.0029) | sun.tuc.noao.edu.domain > nsl.lbl.gov.domain:
5+ A? ftp.ee.lbl.gov. (32) |
| 4 | 19.909242 ( 0.4770) | nsl.lbl.gov.domain > sun.tuc.noao.edu.domain:
5* 2/0/0 CNAME ee.lbl.gov. (72) |
Line 1 shows that this time our server contacts another of the root servers (c.nyser.net). A name server normally cycles through the various servers for a zone until round-trip estimates are accumulated. The server with the smallest round-trip time is then used.
Since our server is contacting a root server, the recursion-desired flag is not set. This root server does not clear the recursion-available flag, as we saw in line 2 in Figure 14.14. (Even so, a name server still should not ask a root server for a recursive query.)
In line 2 the response comes back with no answers, but four authority RRs and four additional information RRs. As we can guess, the four authority RRs are the names of the name servers for ftp.ee.lbl.gov, and the four other RRs contain the IP addresses of these four servers.
Line 3 is the query of the name server nsl.lbl.gov (the first of the four name servers returned in line 2). The recursion-desired flag is set.
The response in line 4 is different from previous responses. Two answer RRs are returned and tcpdump says that the first one is a CNAME RR. The canonical name of ftp.ee.lbl.gov is ee.lbl.gov.
This is a common usage of CNAME records. The FTP site for LBL always has a name beginning with ftp, but it may move from one host to another over time. Users need only know the name ftp.ee.lbl.gov and the DNS will replace this with its canonical name when referenced.
Remember that when we ran host,
it printed both the CNAME and the IP address of the canonical
name. This is because the response (line 4 in Figure 14.15) contained
two answer RRs. The first one is the CNAME and the second is the
A record. If the A record had not been returned with the CNAME,
our server would have issued another query, asking for the IP
address of ee.lbl.gov. This is another
implementation optimization-both the CNAME and the A record of
the canonical name are returned in one response.
14.8 UDP or TCP
We've mentioned that the well-known port numbers for DNS name servers are UDP port 53 and TCP port 53. This implies that the DNS supports both UDP and TCP. But all the examples that we've watched with tcpdump have used UDP. When is each protocol used and why?
When the resolver issues a query and the response comes back with the TC bit set ("truncated") it means the size of the response exceeded 512 bytes, so only the first 512 bytes were returned by the server. The resolver normally issues the request again, using TCP. This allows more than 512 bytes to be returned. (Recall our discussion of the maximum UDP datagram size in Section 11.10.) Since TCP breaks up a stream of user data into what it calls segments, it can transfer any amount of user data, using multiple segments.
Also, when a secondary name server for a domain starts up it performs a zone transfer from the primary name server for the domain. We also said that the secondary queries the primary on a regular basis (often every 3 hours) to see if the primary has had its tables updated, and if so, a zone transfer is performed. Zone transfers are done using TCP, since there is much more data to transfer than a single query or response.
Since the DNS primarily uses UDP, both the resolver
and the name server must perform their own timeout and retransmission.
Also, unlike many other Internet applications that used UDP (TFTP,
BOOTP, and SNMP), which operate mostly on local area networks,
DNS queries and responses often traverse wide area networks. The
packet loss rate and variability in round-trip times are normally
higher on a WAN than a LAN, increasing the importance of a good
retransmission and timeout algorithm for DNS clients.
14.9 Another Example
Let's look at another example that ties together many of the DNS features that we've described. We start an Rlogin client, connecting to an Rlogin server in some other domain. Figure 14.16 shows the exchange of packets that takes place.
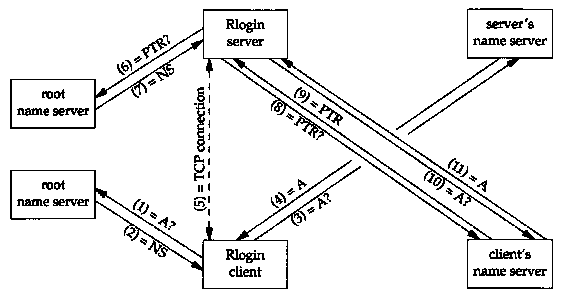
The following 11 steps take place, assuming none of the information is already cached by the client or server:
Caching can reduce the number of packets exchanged
in this figure.
14.10 Summary
The DNS is an essential part of any host connected to the Internet, and widely used in private internets also. The basic organization is a hierarchical tree that forms the DNS name space.
Applications contact resolvers to convert a hostname to an IP address, and vice versa. Resolvers then contact a local name server, and this server may contact one of the root servers or other servers to fulfill the request.
All DNS queries and responses have the same message format. This message contains questions and possibly answer resource records (RRs), authority RRs, and additional RRs. We saw numerous examples, showing the resolver configuration file and some of the DNS optimizations: pointers to domain names (to reduce the size of messages), caching, the in-addr.arpa domain (to look up a name given an IP address), and returning additional RRs (to save the requestor from issuing another query).
14.1 Classify a DNS resolver and a DNS name server as either client, server, or both.
14.2 Account for all 75 bytes in the response in Figure 14.12.
14.3 In Section 12.3 we said that an application that accepts either a dotted-decimal IP address or a hostname should assume the former, and if that fails, then assume a hostname. What happens if the order of the tests is reversed?
14.4 Every UDP datagram has an associated length. A process that receives a UDP datagram is told what its length is. When a resolver issues a query using TCP instead of UDP, since TCP is a stream of bytes without any record markers, how does the application know how much data is returned? Notice that there is no length field in the DNS header (Figure 14.3). (Hint: Look at RFC 1035.)
14.5 We said that a name server must know the IP addresses of the root servers and that this information is available via anonymous FTP. Unfortunately not all system administrators update their DNS files whenever changes are made to the list of root servers. (Changes do occur to the list of root servers, but not frequently.) How do you think the DNS handles this?
14.6 Fetch the file specified in Exercise 1.8 and determine who is responsible for maintaining the root name servers. How frequently are the root servers updated?
14.7 What is a problem with maintaining the cache in the name server, and having a stateless resolver?
14.8 In the discussion of Figure 14.10 we said that the name server sorts the A records so that addresses on common networks appear first. Who should sort the A records, the name server or the resolver?