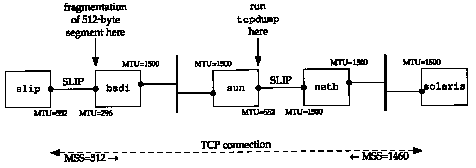
Figure 24.1 Topology for path MTU example.
TCP has operated for many years over data links ranging from 1200 bits/sec dialup SLIP links to Ethernets. Ethernets were the predominant form of data link for TCP/IP in the 1980s and early 1990s. Although TCP operates correctly at speeds higher than an Ethernet (T3 phone lines, FDDI, and gigabit networks, for example), certain TCP limits start to be encountered at these higher speeds.
This chapter looks at some proposed modifications to TCP that allow it to obtain the maximum throughput at these higher speeds. We first look at the path MTU discovery mechanism, which we've seen earlier in the text, focusing this time on how it operates with TCP. This often lets TCP use an MTU greater than 536 for nonlocal connections, increasing its throughput.
We then look at long fat pipes, networks that have a large bandwidth-delay product, and the TCP limits that are encountered on these networks. Two new TCP options are described that deal with long fat pipes: a window scale option (to increase TCP's maximum window above 65535 bytes) and a timestamp option. This latter option lets TCP perform more accurate RTT measurement for data segments, and also provides protection against wrapped sequence numbers, which can occur at high speeds. These two options are defined in RFC 1323 [Jacobson, Braden, and Borman 1992].
We also look at the proposed T/TCP, modifications to TCP for transactions. The transaction mode of communication features a client request responded to by a server reply. It is a common paradigm for client-server computing. The goal of T/TCP is to reduce the number of segments exchanged by the two ends, avoiding the three-way handshake and the four segments to close the connection, so that the client receives the server's reply in one RTT plus the time required to process the request.
What is impressive about these new options-path MTU discovery, the window scale option, the tirnestamp option, and T/TCP - is that they are backward compatible with existing TCP implementations. Newer systems that include these options can still interoperate with all older systems. With the exception of an additional field in an ICMP message that can be used by path MTU discovery, these newer options need only be implemented on the end systems that want to take advantage of them.
We finish the chapter by looking at recently published
figures dealing with TCP performance.
24.2 Path MTU Discovery
In Section 2.9 we described the concept of the path MTU. It is the minimum MTU on any network that is currently in the path between two hosts. Path MTU discovery entails setting the "don't fragment" (DF) bit in the IP header to discover if any router on the current path needs to fragment IP datagrams that we send. In Section 11.6 we showed the ICMP unreachable error returned by a router that is asked to forward an IP datagram with the DF bit set when the MTU is less than the datagram size. In Section 11.7 we showed a version of the traceroute program that used this mechanism to determine the path MTU to a destination. In Section 11.8 we saw how UDP handled path MTU discovery. In this section we'll examine how this mechanism is used by TCP, as specified by RFC 1191 [Mogul and Deering 1990].
Of the various systems used in this text (see the Preface) only Solaris 2.x supports path MTU discovery.
TCP's path MTU discovery operates as follows. When a connection is established, TCP uses the minimum of the MTU of the outgoing interface, or the MSS announced by the other end, as the starting segment size. Path MTU discovery does not allow TCP to exceed the MSS announced by the other end. If the other end does not specify an MSS, it defaults to 536. It is also possible for an implementation to save path MTU information on a per-route basis, as we mentioned in Section 21.9.
Once the initial segment size is chosen, all IP datagrams sent by TCP on that connection have the DF bit set. If an intermediate router needs to fragment a datagram that has the DF bit set, it discards the datagram and generates the ICMP "can't fragment" error we described in Section 11.6.
If this ICMP error is received, TCP decreases the segment size and retransmits. If the router generated the newer form of this ICMP error, the segment size can be set to the next-hop MTU minus the sizes of the IP and TCP headers. If the older ICMP error is returned, the probable value of the next smallest MTU (Figure 2.5) must be tried. When a retransmission caused by this ICMP error occurs, the congestion window should not change, but slow start should be initiated.
Since routes can change dynamically, when some time has passed since the last decrease of the path MTU, a larger value (up to the minimum of the MSS announced by the other end, or the outgoing interface MTU) can be tried. RFC 1191 recommends this time interval be about 10 minutes. (We saw in Section 11.8 that Solaris 2.2 uses a 30-sec-ond timer for this.)
Given the normal default MSS of 536 for nonlocal destinations, path MTU discovery avoids fragmentation across intermediate links with an MTU of less than 576 (which is rare). It can also avoid fragmentation on local destinations when an intermediate link (e.g., an Ethernet) has a smaller MTU than the end-point networks (e.g., a token ring). But for path MTU discovery to be more useful, and take advantage of wide area networks with MTUs greater than 576, implementations must stop using a default MSS of 536 bytes for nonlocal destinations. A better choice for the MSS is the MTU of the outgoing interface (minus the size of the IP and TCP headers, of course). (In Appendix E we'll see that most implementations allow the system administrator to change this default MSS value.)
We can see how path MTU discovery operates when an intermediate router has an MTU less than either of the end point's interface MTUs. Figure 24.1 shows the topology for this example.
We'll establish a connection from the host solaris (which supports the path MTU discovery mechanism) to the host slip. This setup is identical to the one used for our UDP path MTU discovery example (Figure 11.13) but here we have set the MTU of the interface on slip to 552, instead of its normal 296. This causes slip to announce an MSS of 512. But leaving the MTU of the SLIP link on bsdi at 296 will cause TCP segments greater than 256 to be fragmented, and we can see how the path MTU discovery mechanism on solaris handles this.
We'll run our sock program on solaris and perform one 512-byte write to the discard server on slip:
solaris % sock -i -nl -w512 slip discard
Figure 24.2 shows the tcpdump output, collected on the SLIP interface on the host sun.
| 1 | 0.0 | solaris.33016 > slip.discard: S 1171660288:1171660288(0)
win 8760 <mss 1460> (DF) |
| 2 | 0.101597 (0.1016) | slip.discard > solaris.33016: S 137984001:137984001(0)
ack 1171660289 win 4096 <mss 512> |
| 3 | 0.630609 (0.5290) | solaris.33016 > slip.discard: P 1:513(512)
ack 1 win 9216 (DF) |
| 4 | 0.634433 (0.0038) | bsdi > solaris: icmp:
slip unreachable - need to frag, mtu = 296 (DF) |
| 5 | 0.660331 (0.0259) | solaris.33016 > slip.discard: F 513:513(0)
ack 1 win 9216 (DF) |
| 6 | 0.752664 (0.0923) | slip.discard > solaris.33016: . ack 1 win 4096 |
| 7 | 1.110342 (0.3577) | solaris.33016 > slip.discard: P 1:257(256)
ack 1 win 9216 (DF) |
| 8 | 1.439330 (0.3290) | slip.discard > solaris.33016: . ack 257 win 3840 |
| 9 | 1.770154 (0.3308) | solaris.33016 > slip.discard: FP 257:513(256)
ack 1 win 9216 (DF) |
| 10 | 2.095987 (0.3258) | slip.discard > solaris.33016: . ack 514 win 3840 |
| 11 | 2.138193 (0.0422) | slip.discard > solaris.33016: F 1:1(0) ack 514 win 4096 |
| 12 | 2.310103 (0.1719) | solaris.33016 > slip.discard: . ack 2 win 9216 (DF) |
The MSS values in lines 1 and 2 are what we expect. We then see solaris send a 512-byte segment (line 3) containing the 512 bytes of data and the ACK of the SYN. (We saw this combination of the ACK of a SYN along with the first segment of data in Exercise 18.9.) This generates the ICMP error in line 4 and we see that the router bsdi generates the newer ICMP error containing the MTU of the outgoing interface.
It appears that before this error makes it back to solaris, the FIN is sent (line 5). Since slip never received the 512 bytes of data discarded by the router bsdi, it is not expecting this sequence number (513), so it responds in line 6 with the expected sequence number (1).
At this time the ICMP error has made it back to solaris and it retransmits the 512 bytes of data in two 256-byte segments (lines 7 and 9). Both are sent with the DF bit set, since there could be another router beyond bsdi with a smaller MTU.
A longer transfer was run (taking about 15 minutes) and after moving from the 512-byte initial segment to 256-byte segments, solaris never tried the higher segment size again.
Conventional wisdom says that bigger packets are better [Mogul 1993, Sec. 15.2.8] because sending fewer big packets "costs less" than sending more smaller packets. (This assumes the packets are not large enough to cause fragmentation, since that introduces another set of problems.) The reduced cost is that associated with the network (packet header overhead), routers (routing decisions), and hosts (protocol processing and device interrupts). Not everyone agrees with this [Bellovin 1993].
Consider the following example. We send 8192 bytes through four routers, each connected with a Tl telephone line (1,544,000 bits/sec). First we use two 4096-byte packets, as shown in Figure 24.3.
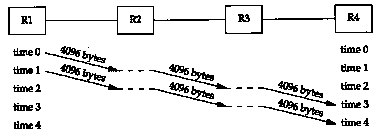
The basic problem is that routers are store-and-forward devices. They normally receive the entire input packet, validate the IP header including the IP checksum, make their routing decision, and start sending the output packet. In this figure we're assuming the ideal case where it takes no time for these operations to occur at the router (the horizontal dashed lines). Nevertheless, it takes four units of time to send all 8192 bytes from Rl to R4. The time for each hop is
(We account for the 40 bytes of IP and TCP header.) The total time to send the data is the number of packets plus the number of hops, minus one, which we can see visually in this example is four units of time, or 85.6 ms. Each link is idle for two units of time, or 42.8 ms. Figure 24.4 shows what happens if we send sixteen 512-byte packets.
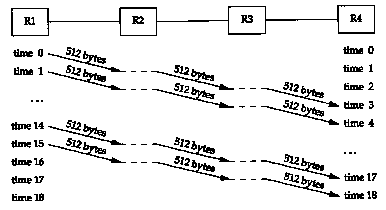
It takes more units of time, but the units are shorter since a smaller packet is being sent.
The total time is now (18 x 2.9) = 52.2 ms. Each link is again idle for two units of time, which is now 5.8 ms.
In this example we have ignored the time required
for the ACKs to be returned, the connection establishment and
termination times, and the possible sharing of the links with
other traffic. Nevertheless, measurements in [Bellovin 1993] indicate
that bigger is not always better. More research is required in
this area on various networks.
24.3 Long Fat Pipes
In Section 20.7 we showed the capacity of a connection as
and called this the bandwidth-delay product. This is also called the size of the pipe between the end points.
Existing limits in TCP are being encountered as this product increases to larger and larger values. Figure 24.5 shows some values for various types of networks.
(bits/sec) | time (ms) | product (bytes) | |
| Ethernet LAN T1 telephone line, transcontinental T1 telephone line, satellite T3 telephone line, transcontinental gigabit, transcontinental | 1,544,000 1,544,000 45,000,000 1,000,000,000 | 60 500 60 60 | 11,580 95,500 337,500 7,500,000 |
We show the bandwidth-delay product in bytes, because that's how we typically measure the buffer sizes and window sizes required on each end.
Networks with large bandwidth-delay products are called long fat networks (LFNs, pronounced "elefan(t)s"), and a TCP connection operating on an LFN is called a long fat pipe. Going back to Figure 20.11 and Figure 20.12, the pipe can be stretched in the horizontal direction (a longer RTT), or stretched in the vertical direction (a higher bandwidth), or both. Numerous problems are encountered with long fat pipes.
The window scale option described in Section 24.4 solves this problem.
Section 21.7 is required to keep the pipe from draining. But even with this algorithm, the loss of more than one packet within a window typically causes the pipeline to drain. (If the pipe drains, slow start gets things going again, but that takes multiple round-trip times to get the pipe filled again.)
Selective acknowledgments (SACKs) were proposed in RFC 1072 [Jacobson and Braden 1988] to handle multiple dropped packets within a window. But this feature was omitted from RFC 1323, because the authors felt several technical problems needed to be worked out before including them in TCP.
The timestamp option, which we describe in Section 24.5, allows more segments to be timed, including retransmissions.
A different problem with TCP's sequence numbers appears with LFNs. Since the sequence number space is finite, the same sequence number is reused after 4,294,967,296 bytes have been transmitted. What if a segment containing the byte with a sequence number N gets delayed in the network and then reappears later, while the connection is still up? This is only a problem if the same sequence number N is reused within the MSL period, that is, if the network is so fast that sequence number wrap occurs in less than MSL. On an Ethernet it takes almost 60 minutes to send this much data, so there is no chance of this happening, but the time required for the wrap to occur drops as the bandwidth increases: a T3 telephone line (45 Mbits/sec) wraps in 12 minutes, FDDI (100 Mbits/sec) in 5 minutes, and a gigabit network (1000 Mbits/sec) in 34 seconds. The problem here is not the bandwidth-delay product, but the bandwidth itself.
In Section 24.6 we describe a way to handle this: the PAWS algorithm (protection against wrapped sequence numbers), which uses the TCP timestamp option.
4.4BSD contains all the options and algorithms that we describe in the following sections: the window scale option, the timestamp option, and the protection against wrapped sequence numbers. Numerous vendors are also starting to support these options.
When networks reach gigabit speeds, things change. [Partridge 1994] covers gigabit networks in detail. Here we'll look at the differences between latency and bandwidth [Kleinrock 1992].
Consider sending a one million byte file across the United States, assuming a 30-ms latency. Figure 24.6 shows two scenarios, the top illustration uses a Tl telephone line (1,544,000 bits/sec) and the bottom uses a 1 gigabit/sec network. Time is shown along the x-axis, with the sender on the left and the receiver on the right, and capacity on the y-axis. The shaded area in both pictures is the one million bytes to send.
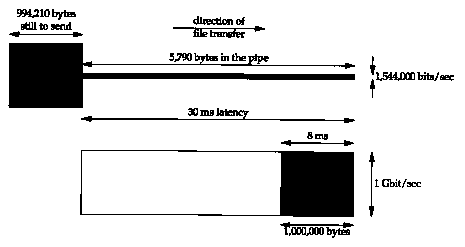
Figure 24.6 shows the status of both networks after 30 ms. With both networks the first bit of data reaches the other end after 30 ms (the latency), but with the T1 network the capacity of the pipe is only 5,790 bytes, so 994,210 bytes are still at the sender, waiting to be sent. The capacity of the gigabit network, however, is 3,750,000 bytes, so the entire file uses just over 25% of the pipe. The last bit of the file reaches the receiver 8 ms after the first bit.
The total time to transfer the file across the T1 network is 5.211 seconds. If we throw more bandwidth at the problem, a T3 network (45,000,000 bits/sec), the total time decreases to 0.208 seconds. Increasing the bandwidth by a factor of 29 reduces the total time by a factor of 25.
With the gigabit network the total time to transfer the file is 0.038 seconds: the 30-ms latency plus the 8 ms for the actual file transfer. Assuming we could double the bandwidth to 2 gigabits/sec, we only reduce the total time to 0.034 seconds: the same 30-ms latency plus 4 ms to transfer the file. Doubling the bandwidth now decreases the total time by only 10%. At gigabit speeds we are latency limited, not bandwidth limited.
The latency is caused by the speed of light and can't
be decreased (unless Einstein was wrong). The effect of this fixed
latency becomes worse when we consider the packets required to
establish and terminate a connection. Gigabit networks will cause
several networking issues to be looked at differently.
24.4 Window Scale Option
The window scale option increases the definition of the TCP window from 16 to 32 bits. Instead of changing the TCP header to accommodate the larger window, the header still holds a 16-bit value, and an option is defined that applies a scaling operation to the 16-bit value. TCP then maintains the "real" window size internally as a 32-bit value.
We saw an example of this option in Figure 18.20. The 1-byte shift count is between 0 (no scaling performed) and 14. This maximum value of 14 is a window of 1,073,725,440 bytes (65535 x 214).
This option can only appear in a SYN segment; therefore the scale factor is fixed in each direction when the connection is established. To enable window scaling, both ends must send the option in their SYN segments. The end doing the active open sends the option in its SYN, but the end doing the passive open can send the option only if the received SYN specifies the option. The scale factor can be different in each direction.
If the end doing the active open sends a nonzero scale factor, but doesn't receive a window scale option from the other end, it sets its send and receive shift count to 0. This lets newer systems interoperate with older systems that don't understand the new option.
The Host Requirements RFC requires TCP to accept an option in any segment. (The only previously defined option, the maximum segment size, only appeared in SYN segments.) It further requires TCP to ignore any option it doesn't understand. This is made easy since all the new options have a length field (Figure 18.20).
Assume we are using the window scale option, with a shift count of S for sending and a shift count of R for receiving. Then every 16-bit advertised window that we receive from the other end is left shifted by R bits to obtain the real advertised window size. Every time we send a window advertisement to the other end, we take our real 32-bit window size and right shift it S bits, placing the resulting 16-bit value in the TCP header.
The shift count is automatically chosen by TCP, based on the size of the receive buffer. The size of this buffer is set by the system, but the capability is normally provided for the application to change it. (We discussed this buffer in Section 20.4.)
If we initiate a connection using our sock program from the 4.4BSD host vangogh.cs.berkeley.edu, we can see its TCP calculate the window scale factor. The following interactive output shows two consecutive runs of the program, first specifying a receive buffer of 128000 bytes, and then a receive buffer of 220000 bytes:
| vangogh % sock -v -R128000 bsdi.tuc.noao.edu echo | |
| SO_RCVBUF = 128000 | |
| connected on 128.32.130.2.4107 to 140.252.13.35.7 | |
| TCP_MAXSEG = 512 | |
| hello, world | we type this line |
| hello, world | and it's echoed here |
| ^D | type end-of-file character to terminate |
| vangogh % sock -v -R220000 bsdi.tuc.noao.edu echo | |
| SO_RCVBUF = 220000 | |
| connected on 128.32.130.2.4108 to 140.252.13.35.7 | |
| TCP_MAXSEG = 512 | |
| bye, bye | type this line |
| bye, bye | and it's echoed here |
| ^D | type end-of-file character to terminate |
Figure 24.7 shows the tcpdump output for these two connections. (We have deleted the final 8 lines for the second connection, because nothing new is shown.)
| 1 | 0.0 | vangogh.4107 > bsdi.echo: S 462402561:462402561(0)
win 65535 <mss 512,nop,wscale l,nop,nop,timestamp 995351 0> |
| 2 | 0.003078 ( 0.0031) | bsdi.echo > vangogh.4107: S 177032705:177032705(0) ack 462402562 win 4096 <mss 512> |
| 3 | 0.300255 ( 0.2972) | vangogh.4107 > bsdi.echo: . ack 1 win 65535 |
| 4 | 16.920087 (16.6198) | vangogh.4107 > bsdi.echo: P 1:14(13) ack 1 win 65535 |
| 5 | 16.923063 ( 0.0030) | bsdi.echo > vangogh.4107: P 1:14(13) ack 14 win 4096 |
| 6 | 17.220114 ( 0.2971) | vangogh.4107 > bsdi.echo: . ack 14 win 65535 |
| 7 | 26.640335 ( 9.4202) | vangogh.4107 > bsdi.echo: F 14:14(0) ack 14 win 65535 |
| 8 | 26.642688 ( 0.0024) | bsdi.echo > vangogh.4107: . ack 15 win 4096 |
| 9 | 26.643964 ( 0.0013) | bsdi.echo > vangogh.4107: F 14:14(0) ack 15 win 4096 |
| 10 | 26.880274 ( 0.2363) | vangogh.4107 > bsdi.echo: . ack 15 win 65535 |
| 11 | 44.400239 (17.5200) | vangogh.4108 > bsdi.echo: S 468226561:468226561(0)
win 65535 <mss 512,nop,wscale 2,nop,nop,timestamp 995440 0> |
| 12 | 44.403358 ( 0.0031) | bsdi.echo > vangogh.4108: S 182792705:182792705(0) ack 468226562 win 4096 <mss 512> |
| 13 | 44.700027 ( 0.2967) | vangogh.4108 > bsdi.echo: . ack 1 win 65535 |
| remainder of this connection deleted |
In line 1 vangogh advertises a window of 65535 and specifies the window scale option with a shift count of 1. This advertised window is the largest possible value that is less than the receive buffer size (128000), because the window field in a SYN segment is never scaled.
The scale factor of 1 means vangogh would like to send window advertisements up to 131070 (65535 x 21). This will accommodate our receive buffer size (128000). Since bsdi does not send the window scale option in its SYN (line 2), the option is not used.
Notice that vangogh continues to use the largest window possible (65535) for the remainder of the connection.
For the second connection vangogh
requests a shift count of 2, meaning it would like to send window
advertisements up to 262140 (65535 x 22), which is greater than
our receive buffer size (220000).
24.5 Timestamp Option
The timestamp option lets the sender place a timestamp value in every segment. The receiver reflects this value in the acknowledgment, allowing the sender to calculate an RTT for each received ACK. (We must say "each received ACK" and not "each segment" since TCP normally acknowledges multiple segments per ACK.) We said that many current implementations only measure one RTT per window, which is OK for windows containing eight segments. Larger window sizes, however, require better RTT calculations.
Section 3.1 of RFC 1323 gives the signal processing reasons for requiring better RTT estimates for bigger windows. Basically the RTT is measured by sampling a data signal (the data segments) at a lower frequency (once per window). This introduces aliasing into the estimated RTT. When there are eight segments per window, the sample rate is one-eighth the data rate, which is tolerable, but with 100 segments per window, the sample rate is 1/IOOth the data rate. This can cause the estimated RTT to be inaccurate, resulting in unnecessary retransmissions. If a segment is lost, it only gets worse.
Figure 18.20 showed the format of the timestamp option. The sender places a 32-bit value in the first field, and the receiver echoes this back in the reply field. TCP headers containing this option will increase from the normal 20 bytes to 32 bytes.
The timestamp is a monotonically increasing value. Since the receiver echoes what it receives, the receiver doesn't care what the timestamp units are. This option does not require any form of clock synchronization between the two hosts. RFC 1323 recommends that the timestamp value increment by one between 1 ms and 1 second.
4.4BSD increments the timestamp clock once every
500 ms and this timestamp clock is reset to 0 on a reboot.
In Figure 24.7, if we look at the timestamp in segment
1 and the timestamp in segment II, the difference (89 units) corresponds
to 500 ms per unit for the time difference of 44.4 seconds.
The specification of this option during connection establishment is handled the same way as the window scale option in the previous section. The end doing the active open specifies the option in its SYN. Only if it receives the option in the SYN from the other end can the option be sent in future segments.
We've seen that a receiving TCP does not have to acknowledge every data segment that it receives. Many implementations send an ACK for every other data segment. If the receiver sends an ACK that acknowledges two received data segments, which received timestamp is sent back in the timestamp echo reply field?
To minimize the amount of state maintained by either end, only a single timestamp value is kept per connection. The algorithm to choose when to update this value is simple.
This algorithm handles the following two cases:
For example, if two segments containing bytes 1-1024 and 1025-2048 arrive, both with a timestamp option, and the receiver acknowledges them both with an ACK 2049, the timestamp in the ACK will be the value from the first segment containing bytes 1-1024. This is correct because the sender must calculate its retransmission timeout taking the delayed ACKs into consideration.
For example, assume three segments, each containing 1024 bytes, are received in the following order: segment 1 with bytes 1-1024, segment 3 with bytes 2049-3072, then segment 2 with bytes 1025-2048. The ACKs sent back will be ACK 1025 with the timestamp from segment 1 (a normal ACK for data that was expected), ACK 1025 with the timestamp from segment 1 (a duplicate ACK in response to the in-window but the out-of-sequence segment), then ACK 3073 with the timestamp from segment 2 (not the later timestamp from segment 3). This has the effect of overestimating the RTT when segments are lost, which is better than underestimating it. Also, if the final ACK contained the timestamp from segment 3, it might include the time required for the duplicate ACK to be returned and segment 2 to be retransmitted, or it might include the time for the sender's retransmission timeout for segment 2 to expire. In either case, echoing the timestamp from segment 3 could bias the sender's RTT calculations.
Although the timestamp option allows for better RTT
calculations, it also provides a way for the receiver to avoid
receiving old segments and considering them part of the existing
data segment. The next section describes this.
24.6 PAWS: Protection Against Wrapped Sequence Numbers
Consider a TCP connection using the window scale option with the largest possible window, 1 gigabyte (230). (The largest window is just smaller than this, 65535 x 214, not 216 x 214, but that doesn't affect this discussion.) Also assume the timestamp option is being used and that the timestamp value assigned by the sender increments by one for each window that is sent. (This is conservative. Normally the timestamp increments faster than this.) Figure 24.8 shows the possible data flow between the two hosts, when transferring 6 gigabytes. To avoid lots of IO-digit numbers, we use the notation G to mean a multiple of 1,073,741,824. We also use the notation from tcpdump that J:K means byte 1 through and including byte K - 1.
sequence# | timestamp | |||
| OK | ||||
| OK but one segment lost and retransmitted | ||||
| OK | ||||
| OK | ||||
| OK | ||||
| OK but retransmitted segment reappears |
The 32-bit sequence number wraps between times D and E. We assume that one segment gets lost at time B and is retransmitted. We also assume that this lost segment reappears at time F.
This assumes that the time difference between the segment getting lost and reappearing is less than the MSL; otherwise the segment would have been discarded by some router when its TTL expired. As we mentioned earlier, it is only with high-speed connections that this problem appears, where old segments can reappear and contain sequence numbers currently being transmitted.
We can also see from Figure 24.8 that using the timestamp prevents this problem. The receiver considers the timestamp as a 32-bit extension of the sequence number. Since the lost segment that reappears at time F has a timestamp of 2, which is less than the most recent valid timestamp (5 or 6), it is discarded by the PAWS algorithm.
The PAWS algorithm does not require any form of time
synchronization between the sender and receiver. All the receiver
needs is for the timestamp values to be mono-tonically increasing,
and to increase by at least one per window.
24.7 T/TCP: A TCP Extension for Transactions
TCP provides a virtual-circuit transport service. There are three distinct phases in the life of a connection: establishment, data transfer, and termination. Applications such as remote login and file transfer are well suited to a virtual-circuit service.
Other applications, however, are designed to use a transaction service. A transaction is a client request followed by a server response with the following characteristics:
One application that we've already seen that uses this type of service is the Domain Name System (Chapter 14), although the DNS is not concerned with the server replaying duplicate requests.
Today the choice an application designer has is TCP or UDP. TCP provides too many features for transactions, and UDP doesn't provide enough. Usually the application is built using UDP (to avoid the overhead of TCP connections) but many of the desirable features (dynamic timeout and retransmission, congestion avoidance, etc.) are placed into the application, where they're reinvented over and over again.
A better solution is to provide a transport layer that provides efficient handling of transactions. The transaction protocol we describe in this section is called T/TCP. Our description is from its definition, RFC 1379 [Braden 1992b] and [Braden 1992c].
Most TCPs require 7 segments to open and close a connection (see Figure 18.13). Three more segments are then added: one with the request, another with the reply and an ACK of the request, and a third with the ACK of the reply. If additional control bits are added onto the segments-that is, the first segment contains a SYN, the client request, and a FIN-the client still sees a minimal overhead of twice the RTT plus SPT. (Sending a SYN along with data and a FIN is legal; whether current TCPs handle it correctly is another question.)
Another problem with TCP is the TIME_WAIT state and its required 2MSL wait. As shown in Exercise 18.14, this limits the transaction rate between two hosts to about 268 per second.
The two modifications required for TCP to handle transactions are to avoid the three-way handshake and shorten the TIME_WAIT state. T/TCP avoids the three-way handshake by using an accelerated open:
If the received CC is not greater than the cached CC, or if the receiving host doesn't have a cached CC for this client, the normal TCP three-way handshake is performed.
The accelerated open avoids the need for a three-way handshake unless either the client or server has crashed and rebooted. The cost is that the server must remember the last CC received from each client.
The TIME_WAIT state is shortened by calculating the TIME_WAIT delay dynamically, based on the measured RTT between the two hosts. The TIME_WAIT delay is set to 8 times RTO, the retransmission timeout value (Section 21.3).
Using these features the minimal transaction sequence is an exchange of three segments:
When the server TCP with the passive open receives this segment, if the client-CC is greater than the cached CC for this client host, the client-data is passed to the server application, which processes the request.
When the client TCP receives this segment it passes the reply to the client application.
The client's response time to its request is RTT plus SPT.
There are many fine points to the implementation of this TCP option that are covered in the references. We summarize them here:
The appealing feature of T/TCP is that it is a minimal set of changes to an existing protocol but allows backward compatibility with existing implementations. It also takes advantage of existing engineering features of TCP (dynamic timeout and retransmission, congestion avoidance, etc.) instead of forcing the application to deal with these issues.
An alternative transaction protocol is VMTP, the
Versatile Message Transaction Protocol. It is described in RFC
1045 [Cheriton 1988]. Unlike T/TCP, which is a small set of extensions
to an existing protocol, VMTP is a complete transport layer that
uses IP VMTP handles error detection, retransmission, and duplicate
suppression. It also supports multicast communication.
24.8 TCP Performance
Published numbers in the mid-1980s showed TCP throughput on an Ethernet to be around 100,000 to 200,000 bytes per second. (Section 17.5 of [Stevens 1990] gives these references.) A lot has changed since then. It is now common for off-the-shelf hardware (workstations and faster personal computers) to deliver 800,000 bytes or more per second.
It is a worthwhile exercise to calculate the theoretical maximum throughput we could see with TCP on a 10 Mbits/sec Ethernet [Warnock 1991]. We show the basics for this calculation in Figure 24.9. This figure shows the total number of bytes exchanged for a full-sized data segment and an ACK.
#bytes | #bytes | |
| Ethernet preamble Ethernet destination address Ethernet source address Ethernet type field IP header TCP header user data pad (to Ethernet minimum) Ethernet CRC interpacket gap (9.6 microsec) | 6 6 2 20 20 1460 0 4 12 | 6 6 2 20 20 0 6 4 12 |
| total |
We must account for all the overhead: the preamble, the PAD bytes that are added to the acknowledgment, the CRC, and the minimum interpacket gap (9.6 microseconds, which equals 12 bytes at 10 Mbits/sec).
We first assume the sender transmits two back-to-back full-sized data segments, and then the receiver sends an ACK for these two segments. The maximum throughput (user data) is then
If the TCP window is opened to its maximum size (65535, not using the window scale option), this allows a window of 44 1460-byte segments. If the receiver sends an ACK every 22nd segment the calculation becomes
This is the theoretical limit, and makes certain assumptions: an ACK sent by the receiver doesn't collide on the Ethernet with one of the sender's segments; the sender can transmit two segments with the minimum Ethernet spacing; and the receiver can generate the ACK within the minimum Ethernet spacing. Despite the optimism in these numbers, [Wamock 1991] measured a sustained rate of 1,075,000 bytes/sec on an Ethernet, with a standard multiuser workstation (albeit a fast workstation), which is within 90% of the theoretical value.
Moving to faster networks, such as FDDI (100 Mbits/sec), [Schryver 1993] indicates that three commercial vendors have demonstrated TCP over FDDI between 80 and 98 Mbits/sec. When even greater bandwidth is available, [Borman 1992] reports up to 781 Mbits/sec between two Cray